Databricks Certified Machine Learning Associate/Professional 試験勉強まとめ
Contents
試験勉強に使用した教材
公式
- Machine Learning Associate Exam Guide
- Machine Learning Professional Exam Guide
- Machine Learning Practitioner Learning Plan
Udemy
- MLflow in Action - Master the art of MLOps using MLflow tool
- Databricks Certified Machine Learning Associate: 4 Mock Exam
- Databricks Machine Learning Associate Practice Tests 2024
その他
- scalable-machine-learning-with-apache-spark-japanese
- Databricks Certified Machine Learning Associate Exam (Exam Topic)
- Databricks Certified Machine Learning Professional Exam (Exam Topic)
- Databricks Certified Machine Learning Associate Exam (IT Exam)
- Databricks Certified Machine Learning Professional Exam (IT Exam)
- 34 Things I Wished I Knew Before My Databricks ML Associate Exam
- Databricks Machine Learning Associate
- Databricks Machine Learning Professional
- Mastering Your Path to Databricks Certification: Tips and Guide for Machine Learning Professional Exam
- Prepare Databricks Machine Learning Professional certification exam
- connecting the dots
試験結果
- Machine Learning Associate
- Databricks Machine Learning : 61 %
- Data Processing : 88 %
- Model Development : 81 %
- Model Deployment : 100 %
- Score : 77.08 % (37 corrects /48 questions)
- Machine Learning Professional
- Experimentation : 83.33 %
- Model Lifecycle Management : 83.33 %
- Model Deployment : 85.71 %
- Solution and Data Monitoring : 88.88 %
- Score : Nan % ( Nan corrects / 59 questions)
まとめ
試験対策
| 質問 | 回答 |
|---|---|
| 機械学習ライブラリ導⼊済クラスターの選択⽅法 | ML付きのランタイム名をプルダウンで選択 |
| ワークフロー画⾯でジョブが失敗したことを確認する⽅法 | タスク画⾯を確認 |
| モデルのステージ情報はMLflow画⾯のどのページで確認できるか | モデル画⾯のページ |
| mlflowで最良モデルを取得するコード | mlflow.search_runs(experiment_ids=id,order_by=['metric.mae']).loc[0] |
| Feature Storeのメタデータを取得する関数 | fs.get_table("tabel_name") |
| spark dataframeのプロファイリング結果をビジュアルに可視化するコード | dbutils.data.summarize(sdf) , sdf.describe(), sdf.summary()(summary > describeの情報量) |
| spark dataframeで特定列を取得するコード | df.filter(col('col_name')=='value') |
| fit関数のコードでエラーが出た理由 | ⼊⼒値をVectorAssemblerでベクトル化してないから |
| One-Hot Encoding(OHE)のコードでエラーが出た理由 | StringIndexerでラベルインデックスを付与してないから |
| One-Hot Encoding(OHE)済データをFeature Storeに⼊れるべきではない理由 | MLアルゴリズムによってはOHEしない⽅が良い場合があるから |
| imputerによる連続値の補完方法 | mean, median |
| imputerによるカテゴリ変数・離散変数の補完方法 | mode (ただし、Imputerは数値特性のみをサポートしているため、カテゴリ変数は数値ラベルに変換する必要がある) |
| 機械学習をMLflowで⼊れ⼦実⾏する⽅法 | ⼦ジョブにnested=True引数を指定する |
| 評価指標でaccuracyよりもF1が優れる点 | 正例数と負例数のバランスが悪い時 |
| AutoMLでできないこと | デプロイ操作 |
| ターゲット変数のlogを取って機械学習した後にRMSEで評価する場合に必要な処理 | 予測結果をexponent関数で元に戻す |
| Scikit-LearnとPySparkの決定⽊モデルのアルゴリズムの違い | PySparkの場合、入力特徴量のうちカテゴリ変数の最大ユニーク数以上の値をmaxBinsに指定する必要がある |
| cross-validationよりもtrain-testの⽅が優れているとき | 計算時間とリソースが限られている場合 |
| 3層cross-validationで、2つのハイパーパラメータそれぞれ2.3パターンでgrid searchする時の合計学習回数 | 18回(3×2×3) |
| HyperOptを分散処理で実⾏する関数 | SparkTrial |
| HyperOptの精度を向上するためのパラメータ | max_evals |
| HyperOptのハイパーパラメータ探索最適化アルゴリズム | Tree-structured Parzen Estimator |
| Random Forestで利⽤されている⼿法 | bagging |
| Pandas UDFの引数にIteratorを取る利点 | モデル呼び出し処理が1回で済む |
| Pandas UDFの引数にIteratorが指定されている関数の呼び出し⽅ | 引数のスキーマ名の⽂字列を指定するコード |
| Pandas dataframeをPandas API on Sparkに変換する関数 | pyspark.pandas.Dataframe(pdf) |
| mapInPandasとapplyInPandasの使い分け | mapInPandasはDataFrameの各パーティションに関数を適用、mapInPandasはDataFrame 内のグループ化されたデータに関数を適用 |
| Spark ML を使用するデータサイエンスプロジェクトで一番最初に行うべきこと | Spark MLのインポートとSpark Sessionの作成 |
| AutoML 時系列予測で horizon はどんなパラメータ | 将来の予測期間の対象範囲を定義 |
| Spark DataFrameに対してPandas UDF関数内でPandas API構文が使える理由 | Apache Arrowを利用してSparkとpandasのフォーマット間でデータを変換 |
| SparkTrials を使用して Hyperopt で小さなデータセット (約 10 MB 以下) を操作する場合、データセットを読み込むための推奨される方法 | データセットをドライバーにロードし、目的関数から直接呼び出し |
| FeatureStoreのテーブルで、主キーがある場合は行を更新し、ない場合は保持する方法 | fs.write_table( name="features", df=features_df, mode="merge") (overwriteはない行が保持されず消える) |
| 並列処理のコア数を上げることでチューニングプロセスが最も高速化されるシナリオ | データセット全体が各コアで使用可能なメモリに収まり、データの効率的な分散と処理が可能になる場合 |
| 既存の pandas ベースのノートブックのリファクタリングに必要な時間と労力を最小限に抑える方法 | pandas API on Spark |
| Hyperopt で実際のパラメーター値を取得する方法 | hyperopt.space_eval() |
| 自動スケーリング クラスターで SparkTrials を使用しないほうがよいのはなぜ | Hyperoptは実行開始時に並列処理を選択し、自動スケーリングが並列処理に影響を与える可能性がある |
trial = client.search_runs(experiment_id, order_by=[""attributes.start_time desc""], max_results=1)) のメトリクスを取得する方法 | trial[0].data.metrics |
| 外部イベントまたはトリガーに基づいてタスクをオーケストレーションする機能 | Event-Driven スケジューリング |
| Hyperopt における SparkTrials クラスの役割 | トライアルを Spark ワーカーに配布することで、単一マシンのチューニングを高速化 |
| 反復計算を高速化するために中間データをメモリにキャッシュできる Spark の機能 | Spark RDD (Resilient Distributed Datasets) |
| Databricks 環境のクラスターで実行されるすべてのノートブックでPython ライブラリをnewpackage使用できるようにする方法 | クラスターのbash initスクリプトに /databricks/python/bin/pip install newpackage を追加 |
| Databricks AutoML で回帰モデルのパフォーマンスを評価するためのデフォルトの評価指標 | R2(ただし他の指標も計算は行われる) |
| Spark ML で非常に大規模なデータセットの線形回帰問題の実行方法 | 勾配降下法 |
| モデルのStageを移行するスクリプト | client.transition_model_version_stage( name = "your_model_name" 、version = your_model_version 、stage = "Production" ) |
| SparkTrials を使用するときに MLflow 実行を管理するための推奨されるアプローチ | fmin() の呼び出しを mlflow.start_run() でラップして、個別の MLflow メイン実行を確保 |
| 反復アルゴリズムを高速化し、ディスク I/O を削減するために中間データをメモリに保存する手法 | インメモリ計算 |
| AutoML のfeature_store_lookupsパラメータの目的 | データ拡張のために Feature Store から特徴量を取得 |
| マルチシリーズ予測で、データセット内の各時系列を一意に識別するために必要なパラメータ | identity_col |
| 既存のモデル バージョンのメタデータを更新して、説明を変更したり、タグを追加する方法 | mlflow.update_model_version |
| 共有 Databricks クラスター上のすべてのチーム メンバーが etl_utils ライブラリを利用できるようにするための最も推奨される方法 | クラスターのinitスクリプトで dbutils.library.installPyPI("etl_utils") コマンドを使用 |
| モデルの Docker イメージの作成に役立つ MLflow コマンド | mlflow.build_docker_image |
| Spark の pandas API で変換すると PySpark の DecimalType に合致するPythonデータ型 | decimal.Decimal |
| Spark on Pandas API で、compute.ops_on_diff_frames オプションを True に設定する目的 | 2つの異なるデータフレーム間の操作を可能にする |
| 高いカーディナリティを持つカテゴリ機能にワンホットエンコーディングを適用するときの懸念 | 次元の呪いが発生する可能性、メモリ使用量の増加 |
| Sparkで線形回帰モデルを安定的に収束させる方法 | 全ての特徴ベクトルを単位分散に事前スケーリング(スケーリングされていない場合、値の大きな特徴量が最適化プロセスを支配する) |
| SparkTrialsをHyperoptと併用する際の課題 | 並列処理数と利用可能なクラスターリソースのトレードオフを管理(クラスターリソースの競合が発生しない範囲で並列処理数を増やす) |
| 線形回帰モデルのスケーラビリティを評価するために最も重要なメトリクス | 反復回数 |
| Spark DataFrame と Pandas DataFrame の違い | Spark DataFrame は複数ノードにわたる分散コンピューティング用に最適化されており、Pandas DataFrame は単一ノードのメモリ内コンピューティング用に設計されている |
| Spark ML の分散性に関連して、決定木をスケーリングする際に注意すべき点 | 決定木を複数ノードに分散するには、メモリリソースと通信オーバーヘッドを適切に処理する必要がある(決定木を複数ノードに分散する場合、モデル構築プロセスを同期するために、ノード間の通信が必要) |
| 線形回帰モデルのスケーリング効率を向上させるために、Sparkで一般的に使用される最適化手法 | 勾配降下法 |
| train-test 分割がクロスバリデーションよりも好まれる状況 | 時系列データの分割 |
| ブースティングがバギングに比べて優れている点 | 不均衡データに対する予測結果を効果的に活用可能 |
| PySpark DataFrame と Pandas DataFrame on Spark 間のデータ変換における課題 | 変換中にメモリ不足エラーが発生しないようにメモリ使用量を管理 |
| アンサンブル学習はバイアスとバリアンスに対してどのような影響がある | バイアスとバリアンスの両方を低減可能 |
| クロスバリデーションの利点 | より大部分のデータを用いてモデルの学習が可能なので、モデルの汎化性が向上する |
| Feature Store Table を使用してモデルをスコアリングする際の重要事項 | 特徴量取得の待ち時間(レイテンシ)とデータの鮮度のバランスを取る |
| Spark ML で大規模データに対する学習効率が高くなる理由 | Spark はクラスター全体のメモリにデータを保持し、データアクセス速度の早いインメモリコンピューティングが可能なため |
| Spark ML で決定木を使う際の課題の対策 | データセットのサイズが大きくなるにつれ計算の複雑さが増すため、モデル精度への影響が小さいブランチを削除するプルーニングを使用 |
| Pandas UDF を使用して機械学習モデルを並列処理する場合、最適なパフォーマンスを確保するための方針 | UDF内でのモデルのロードのオーバーヘッドを最小限に抑えるため、モデルのシリアライズ形式を選択 |
| Feature Store Table のスキーマ更新で望ましい方針 | スキーマ進化機能を使用して、既存のデータやモデルに影響を与えずに新しい列を追加 |
| MLflow UI でモデルステージ遷移に承認が必要な場合、リクエストを送る方法 | 「遷移をリクエスト」ボタンを使用 |
| Estimator と Transformer の役割 | Estimator はDataFrameにfitしてモデルを生成、Transformer はDataFrameを別のDataFrameに変換 |
| Iterator UDF が大規模データセットで便利な理由 | 小さなチャンクにデータを分割して処理を行うため、メモリ使用量を削減可能 |
| 機械学習モデルの処理をパイプライン化する利点 | モデルのチューニングプロセスの単純化が可能 |
| 効率的でスケーラブルな Spark ML パイプラインを構築する際に重要な考慮事項 | Spark での並列処理用に分散および最適化された変換とアルゴリズムを選択 |
| Spark で線形回帰する際に特徴の正規化がモデルのパフォーマンスと結果に与える影響 | 勾配降下アルゴリズムの収束を高速化 |
| 必要なライブラリをクラスターにインストール方法 | Databricks UI を使用してクラスター設定に移動し、統合パッケージ マネージャーを使用してライブラリをインストール |
| AutoML ので最も精度の高いモデルのソース コードを確認できる場所 | AutoMLの実行を記録しているExperiment内 |
| Spark ML の分散環境での交差検証の方法 | 1つのクラスター内で各フォールドの評価を並列化(複数クラスターを使用する場合、クラスターリソースが増加し、トレーニング時間が長くなる可能性がある) |
| Feature Store Table の作成手順 | テーブルのスキーマとデータ型を定義し、SQL クエリを使用して Delta Lake にテーブルを作成 |
| Pandas UDF が Spark での機械学習モデルの並列処理に及ぼす効果 | データのパーティションに対してベクトル化された操作が可能になり、クラスター全体での並列実行が可能 |
| モデルレジストリでモデルのステージを移行する方法 | MlflowClient の transition_model_version_stage メソッドを使用(モデル レジストリ UI を使用して、ステージを手動で変更も可能) |
| 特定の MLflow Runの実行時間と正確なコードを確認できる場所 | ExperimentのRun内のタイムスタンプとコードスナップショット |
| ブースティングがバギングよりも大幅なパフォーマンス向上をもたらす可能性があるシナリオ | ベースモデルが非常に複雑で、過剰適合が発生しやすい場合 |
| 大規模なデータセットを扱う際に Spark の決定木のスケーラビリティを向上させる主な戦略 | ビニングを使用して連続的な特徴を離散化し、考慮すべき分割の数を減らす |
| クラスターを ML 用の新しい Databricks Runtime バージョンにアップグレードするときに不要な手順 | アップグレード後に、以前にインストールしたすべての Python ライブラリを手動で再インストール |
| Spark ML でトレーニングされた機械学習モデルをリアルタイム予測環境に展開する際に直面する課題 | 予測を行う際に、Spark の分散特性によって生じるレイテンシを管理 |
| Pandas API on Spark を使用してクラスター全体でデータをシャッフルする必要がある操作を実行するときに発生する可能性のある問題 | ネットワークのオーバーヘッドとディスク I/O により、パフォーマンスが大幅に低下する可能性(クラスター内の異なるノード間でのデータの移動が伴うため) |
| F1 スコアよりもリコールを優先するシナリオ | 偽陰性のコストが偽陽性のコストよりも大幅に高い場合 |
| Spark で Pandas API を使用する場合、InternalFrame が処理速度に及ぼす影響 | データシリアル化プロセスをバイパスできるようにすることで、処理速度を最適化(InternalFrameはPandasとSparkのAPIの違いを吸収し、ユーザーにとって統一的なインターフェースを提供する基盤) |
| スタッキングアンサンブルにおけるメタモデルの役割 | ベースモデルの予測結果をもとに最終予測を出力 |
| 分散モデル推論を行うために、UDFを実装する必要のあるライブラリ | Scikit-learn |
| CVパイプラインにモデルを組み込むデメリット | データ前処理までは共通の前処理済みデータを1回作成するだけでよいが、各CVごとに前処理パイプラインも実行されてしまう |
| imputerを用いた欠損値の補完がうまくいかない理由 | transformメソッドを呼ぶ前に、fitメソッドを呼び、imputer_modelを作成する必要があるから |
| CrossValidator をパイプライン内に配置したほうが良いケース | パイプラインにEstimatorやTransformerがある場合(パイプライン全体を CrossValidator に配置すると、毎回推定器を再調整する必要があるため) |
| MLflow モデルレジストリの Webhook を作成する方法 | Databricks REST API を使用して、必要なイベント タイプとターゲット URL で Webhook を作成 |
| 単一ノードクラスターが推奨されるのはどのような場合 | 少量のデータを使用するジョブや、シングルノードの機械学習ライブラリなどの非分散ワークロード |
| クラスタにライブラリをインストールする方法 | 説明ページ |
| Databricks AutoMLのデフォルトの評価指標 | r2(回帰), f1(分類), smape(時系列予測) |
| AutoMLで最も良いモデルの取得 | summary.best_trial |
| ジョブとタスクの関係 | ジョブは1つ以上のタスク(つまりマルチタスク) で構成される |
| Feature Store と Unity Catalog の関係 | Unity Catalog が有効になっているワークスペースの場合:DataFrame を Unity Catalog の Feature Table として書き込み、ワークスペースで Unity Catalog が有効になっていない場合:DataFrame を Workspace Feature Store の Feature Table として書き込み |
| 既存のデルタ テーブルを Feature Table として登録する方法 | fs.register_table(delta_table='schema.table', primary_keys=['key'], description='') |
fs.get_table で得られる情報 | Feature Table のメタデータ |
fs.create_training_set の正しい記述 | training_set = fs.create_training_set(df=df, feature_lookups=feature_lookups, label= None, exclude_columns=[ 'customer_id' ] ) |
feature_lookups の正しい記述 | feature_lookups = [ FeatureLookup( table_name= 'schema.table', feature_names=[ 'feature_name' ], lookup_key= 'key', ), ] |
| 回帰モデルを評価するスクリプト | evaluator = RegressionEvaluator() evaluator.setPredictionCol( "pred" ) |
| 同じデータとパラメータが使用されているにもかかわらず、scikit-learn と Spark ML で結果が異なる可能性がある理由 | Spark ML は確率的勾配降下法、Scikit-learn は行列操作でそれぞれモデルを作成しているため、データに局所最適値がある場合に、異なる結果が生じる可能性がある |
| 分散コンピューティング環境でグラフデータを効率的に分析するために有効な手法 | グラフインデックスの作成 |
| Pandas API on Spark の compute.default_index_type オプションの役割 | 新しい DataFrame を生成するときに作成されるインデックスのデフォルトのタイプ(sequence / distributed / distributed-sequence)を制御 |
| MLflow でログに記録されたパラメーターとタグの名前の競合の解決方法 | 競合のある名前に UUID を追加 |
| 時系列データを効率的にインデックス付けして取得できる手法 | Temporal Indexing |
| リアルタイム分析のために地理空間データを効率的にインデックス化して取得できる手法 | Real-time Geospatial Indexing |
| マルチメディアデータのデータシリアル化の処理方法 | マルチメディアデータをバイトストリームに変換 |
| 分散コンピューティングシステムにおけるデータのコロケーションとは何か | システム内の同じノードまたはノード セットに関連または相関するデータをまとめて保存すること(ノード間の通信を最小限に抑えるため) |
| バイアスとバリアンスのトレードオフを理解することの重要性 | モデルのアンダーフィッティング(高バイアス)とオーバーフィッティング(高バリアンス)のバランスをとり、最適なパフォーマンスを実現 |
| 不均衡なデータセットを検出した場合、AutoML が行う処理 | クラスの重みを追加し、主要なクラスをダウンサンプリング |
| Spark DataFrame 上の単一ノードモデルの推論をスケーリングする際の Iterator を使用する利点 | モデルはバッチごとに1回ではなく、エグゼキュータごとに1回ロードするだけでよい |
| SparkTrials が Hyperopt でチューニングタスクを分散処理する方法 | 各トライアルはドライバーノード上のSparkジョブで生成され、ワーカーノードで評価される |
| SparkTrials を使用して Hyperopt で大規模なデータセット (約 1 GB 以上) を操作する場合、データセットを効率的に処理する方法 | データセットを DBFS に保存し、DBFSからワーカーに再ロード(ドライバーノードを経由せず。データロード可能) |
| DataFrame.transform() と DataFrame.apply() の相違点 | transform では関数が入力と同じ長さを返す必要があるが、apply では任意の長さが許可される |
| AutoML である列にカスタム補完方法が指定されている場合の処理 | これらの列に対してはセマンティック型 (カテゴリ、数値、日付/時刻など) の検出は実行しない |
| Spark DataFrames と比較して、pandas API を使用するとパフォーマンス速度が低下する潜在的な理由 | すべての処理操作の即時評価 |
| AutoML の時系列予測で、時系列内のあるタイムスタンプに複数の値がある場合の処理 | 値を平均化し、あるタイムスタンプで1つの値に集約 |
| クラスの不均衡に対処し、モデルのパフォーマンスを向上させるのに適した Spark ML アルゴリズム | SMOTE (Synthetic Minority Over-sampling Technique):ランダムサンプリングのデータと、k近傍法のアルゴリズムで求められたデータにより、合成データを作成する方法 |
| 複数の小さなタスクを 1 つの大きなタスクに組み合わせて、スケジュールのオーバーヘッドを削減し、処理効率を向上させる手法 | Task Aggregation |
| Spark で複数のノードに ML モデルを分散する際の主な課題 | ネットワークのオーバーヘッドを最小限に抑えるために、ノード間でデータのシリアル化とデシリアル化を管理 |
| DBFS に保存されているデータセットのサイズを確認するコマンド | dbutils.fs.stats("/path/to/dataset") |
| Databricks の機械学習プロジェクトの場合、Python パッケージの依存関係を管理するのに最も効果的なアプローチ | すべての依存関係を含む Docker コンテナを作成し、Databricks にデプロイ |
| 分散データセットのデータの偏りの問題を軽減するのに有効な Spark ML の機能 | 適応型クエリ実行を使用して、データのレイアウトと分散を動的に最適化(ワークロードをノード間で均等に分散) |
| バギングにおけるアウトオブバッグ (OOB) エラーの重要性 | 内部検証メカニズムとして機能し、アンサンブルモデルのエラー率を算出(トレーニングで使用されなかった平均1/3程度のデータのサブセットを用いて計算される各ベースモデルの平均エラー率) |
| パフォーマンスが低いストレージタイプ | ファイルベースのストレージシステム(Googleドライブ、Dropboxなど) |
| モデルレジストリ Webhook が MLflow でのモデルライフサイクルの自動化方法 | モデルバージョンの変更に基づいてアクションをトリガー |
| MLflow ワークフローで ModelSignature を定義する目的 | 入出力フォーマットの標準化 |
| Delta テーブルが効率的な制御のためにストレージとコンピューティングを統合する方法 | データと処理を同じ場所に配置 |
| 更新されたモデルがより最近のデータに対してより優れたパフォーマンスを発揮するかを確認する方法 | ホールドアウトデータセットでのモデルのパフォーマンス評価 |
| 事前計算されたバッチ予測をクエリする場合のライブサービングの利点 | データサイズに関係なく一貫したクエリ速度 |
| Databricks のテーブルから予測の読み取りを高速化する方法 | 頻繁なクエリにデルタキャッシュを活用 |
| Databricks の共通列を使用してクエリを高速化する方法 | テーブルに Z オーダーを適用 |
| 1 つの汎用クラスターを使用したモデルサービングで、複数のモデル間で一貫性が保持されるもの | 複数のデプロイされたモデル間で共有されるリソース(CPU、メモリ、処理能力など) |
| レコメンデーションで推奨される推論方法 | リアルタイム推論 |
| モデル固有の Webhook を作成、変更、削除、またはテストするために必要な権限 | CAN MANAGE |
| レジストリ全体の Webhook を作成、変更、削除、またはテストするために必要な権限 | WORKSPACE ADMIN |
| MLflow Model Registry に登録されたモデルを削除するスクリプト | mlflow.delete_registered_model(name) |
| MLflow Model Registry の特定のバージョンのモデルを削除するスクリプト | mlflow.delete_model_version(name, version) |
| MLflow Model Registry と合わせて、Databricks Jobs を使う利点 | モデル管理とデプロイの流れを効率化 |
| fs.write_table() でサポートされている書き込み方法 | Overwrite と Merge |
| 学習済みモデルを用いて Spark UDF を作成するスクリプト | mlflow.pyfunc.spark_udf() |
| Spark UDF を用いてモデルをデプロイする際に考慮すべきこと | モデルが PySpark API と適合すること |
| バッチデプロイ時に、シングルノードモデルに対して Spark UDF を用いる理由 | 複数ノードで並列分散処理するため |
| ストリーミング処理における、ステートフル処理とステートレス処理の相違 | ステートフル処理は前回までのデータ処理箇所の情報を必要とし、ステートレス処理は独立して処理可能 |
| スキーマを推論するスクリプト | mlflow.models.infer_signature(input, output) |
| 学習したモデルを用いて、Databricks 内でエンドポイントを作成する方法 | モデルレジストリにモデルを登録して、モデルサービングでモデルをデプロイ |
| 数値データのドリフト検知テストとして使用できる手法 | Kolmogorov-Smirnov test |
| ステートフルストリーミングの活用例 | 集計、ウィンドウ処理 |
| Feature Store のベストプラクティス | 特徴量の一貫した命名規則に従う |
| データドリフトに関する検定による監視の目的 | 学習データの特徴量分布と本番データの特徴量分布を比較 |
| Databricks AutoML で最も精度の高いモデルのコードの確認方法 | Best Trial Notebook リンクを開く |
| Delta Tableをストリーミングで読み込むコード | spark.readStream |
| Delta Lakeフォーマットのパスからデータを読み込むコードを選べ | spark.read.load(path) |
| Delta Tableのタイムトラベルの最初の履歴を選ぶコードを選べ | SELECT * FROM table VERSION AS OF 0 |
| Feature Storeのテーブルを上書きするオプション | ‘overwrite’ |
| あらゆる機械学習ライブラリでメトリックのautologを有効にする方法 | mlflow.autolog() |
| pathにあるファイルをMLflow Trackingにartifactsを記録するコードを選べ | mlflow.log_artifacts(local_dir, artifact_path=path) |
| shap値を記録したcsvファイルはMLflow Trackingのどこに記録するか | artifacts |
| mlflow runをネスト実行する方法 | 子runにnetsted=trueを追加 |
| mlflow flavorsのpyfuncを利用する利点を次から選べ | 関数の内容をカスタマイズ可能 |
| mlflow.pyfunc.PythonModelを継承した前処理を含むカスタムモデルが正しく動くようにpythonコードを修正せよ | load_context() メソッドを実装 |
| mlflow model registryのモデルのstatusの状態一覧を次から選べ | None, Staging, Production, Archived |
| MLflow Webhookで利用するJob IDはどこから取得できるか | API, UI |
| MLflow Webhookをジョブに登録した後に、どのような操作をするとジョブが起動するか | Model Registryのモデルのstatusを変更 |
| MLflow Webhookを削除するAPIのURLを選べ | /api/2.0/mlflow/registry-webhooks/delete |
| 複数カラムを条件に指定した場合で、条件に合致するデータファイル読込数を削減するように性能を向上させる手法 | z-ordering |
| mlflow.pyfunc.spark_udf()を利用して予測するコードを選べ | model_udf = mlflow.pyfunc.spark_udf(spark, model_path) df = input_data.withColumn("prediction", model_udf()) |
| Jensen-Shanon Distanceの欠点 | 自分で閾値を設定する必要がある |
| KS検定の欠点 | サンプルサイズの影響を受けやすい |
| 特定の時系列同士でカテゴリ列の分布を比較する手法 | contingency table(分割表) |
| あるカテゴリ列の特徴量で、本番モデルでは学習時よりもnullが多く入っている場合に、統計的な有意性を検証する手法 | One-way Chi-squared Test(カイ二乗適合度検定) |
| Feature Tableのメタデータを取得するコード | fs.get_table("new_table").description |
| モデルオブジェクトをパイプラインの最終段階に配置することによる悪影響は何 | 特徴量エンジニアリングのステップにおいてバリデーションデータが使用されてしまう |
| Spark DataFrames と pandas API on Spark DataFrames の関係として適切な説明 | pandas API on Spark DataFrames は Spark DataFrames と付随するメタデータから構成される |
| データをロードし、star_rating列を削除するコード | spark.read.format(“delta”).load(path).drop(“star_rating”) |
| exp_id に対するランレベルの結果をSpark DataFrameで取得するコード | mlflow.search_runs(exp_id) |
| Spark DataFrameを学習用DataFrameとテスト用DataFrameにランダムに分割するために使用できるSpark操作 | DataFrame.randomSplit |
| 以下の特徴量エンジニアリングタスクの中で、分散処理において最も非効率的な処理 | 欠損値を中央値で補完(中央値の計算はデータのソートが必要なため、大規模データセットの分散処理において最も非効率) |
| 標準的な PySpark UDF の代わりにベクトル化された pandas UDF を使用する利点 | ベクトル化された pandas UDF はデータを1行ずつではなくバッチ単位で処理 |
| SparkのDataFrameをpandas風のAPIで操作するスクリプト | import pyspark.pandas as ps df = ps.DataFrame(spark_df) |
| 過去のデルタテーブルを確認するSQLコマンド | DESCRIBE HISTORY |
| ラベルドリフトとは | 目的変数の分布に変化があるとき |
| MLflow Model Serving で自動的にデプロイされ、リアルタイムでクエリ可能なステージ | Staging, Production |
| MLflow AutologgingとHyperoptを使用する場合、ハイパーパラメータ探索プロセス全体を1つの親ラン(parent run)として管理し、各ハイパーパラメータの組み合わせを子ラン(child run)として記録する方法 | fminを呼び出す前に手動で親ランを開始(各ハイパーパラメータの組み合わせについては、objective_function内で子ラン(nested=True)として記録される) |
| MLflowでSignatureを記録する利点 | モデルサービング時に入力データの型を検証できるため、予期しないエラーを防ぐことが可能 |
| Databricks で spark df のプロファイルを出力するコード | dbutils.data.summarize(df) |
知識
特徴量エンジニアリング
- 欠損値の影響
- モデルパフォーマンスの低下
- バイアスがかかる(偏ったデータ表現)
- モデル操作時の複雑度の増加
- 欠損値の扱い
- 方針
- 欠損を行/列単位で削除
- 欠損をカテゴリとして扱う
- 補完
- 平均値、中央値などの統計量
- 近傍データ
- 他の特徴量を用いた回帰予測
- 注意点
- データの特徴ごとに、適切な方針は異なる
- 欠損のあるデータは離散値、連続値、カテゴリのどれか
- データの分布が正規分布に従わない場合は、平均値より中央値のほうが良い
- 欠損値が多い場合は、統計量よりも近傍データや回帰予測のほうが良い
- 欠損にパターンはあるか確認
- 補完する際は、補完したデータかを示すフラグ列を追加する
- 方針
- カテゴリデータのエンコーディング
- One-Hot Encoding:カテゴリの数だけ列を追加し、各列の0/1で該当カテゴリであるかを表示
- Label Encoding:カテゴリを数値に変換して表示(数値の大小には意味がない点に注意)
- Target Encoding:各カテゴリの予測対象列の値の統計量に置き換え(バイアス、少数カテゴリに注意)
- Categorical Embedding:各カテゴリを対応する埋め込みベクトルに置き換え
- データの正規化
- 特徴量スケールに敏感
- 線形モデル
- SVM
- KNN
- NN
- 特徴量スケールに頑健
- ツリー系モデル
- PCA
- 特徴量スケールに敏感
- 欠損値の補完やデータの正規化は、データセット分割を行った後に実施する
- 予測データを含んだ状態でそれらの操作を行うと、モデルが予測時に使用できないデータを使用することになりリークにつながる
Feature Store
- データサイエンティストがモデルのトレーニングと推論のための特徴量を保存し共有するための機能
- point-in-time correctnessをサポートすることで、時系列やイベントベースのユースケースに対応
- ワークスペースのフィーチャーストアとUnity Catalogのフィーチャーストアの違いは、ワークスペースがUnity Catalogに対応していない場合にワークスペースのフィーチャーストアが使用され、対応している場合はUnity Catalogがフィーチャーストアになる
- フィーチャーストアによって、バッチスコアリングまたはオンライン推論のために特徴量を自動的に取得可能となる
- Unity Catalogでフィーチャーテーブルを削除するには、カタログエクスプローラーUIから操作する(Python APIはない)
評価指標
- 回帰モデルにおけるR二乗は、変数の分散の割合を定量化
- RMSEはターゲット変数との単位の一貫性を維持し、MSEと比較して解釈性が向上
- 適合率(Precision)は、モデルが陽性と予測するときの正答率に特化
- 再現率(Recall)は、真陽性に対する正答率に特化
- 偽陰性のコストが高い場合、適合率よりも再現率のほうが適している
AutoML
- 回帰、分類、時系列予測のプロトタイプを迅速に作成可能
- 学習モデルごとにノートブックが提供されるため、学習の過程を確認可能
- モデルに応じて適切なメトリクスも自動で計算される(特徴量重要度、混同行列、SHAPなど)
- MLflowとの連携も簡単
MLflow
- MLflowには4つの主要コンポーネントがある
- MLflow Tracking:実験の記録と管理

MLflow Trackingの構成要素 - MLflow Projects:コード・環境・データなどをパッケージ化し、共有のしやすさと実験の再現性を向上
MLflow Projectsの構成要素 - MLflow Models:モデルの保存と推論環境の標準化
MLflow Modelsの構成要素 - MLflow Registry:モデルのバージョン・ステージなどのライフサイクルを管理
MLflow Registryの構成要素
- MLflow Tracking:実験の記録と管理
- MLflow Model (Flavor) は各モデルや依存関係を記述したファイルを含むディレクトリ
- signature, input example などの追加データも含むことが可能
- e.g.) signatureの追加方法
from mlflow.models.signature import ModelSignature, infer_signature from mlflow.types.schema import Schema, ColSpec # 手動指定 input_data = { {"name": "{name}", "type": "{data_type}"}, {"name": "{name}", "type": "{data_type}"}, {"name": "{name}", "type": "{data_type}"} } output_data = { "type": "{data_type}" } input_schema = Schema(ColSpec(col["type"], col["name"]) for col in input_data) output_schema = Schema(ColSpec(col["type"]) for col in output_data) signature = ModelSignature(input=input_schema, output=output_schema) mlflow.log_model(model, "{model_name}", signature) # 自動推論 signature = infer_signature(x, y)
mlflow uiコマンドで、MLflowの実験履歴をGUI上で確認可能- Tracking Server:自分で指定した方法でトラッキングサーバーを作成
- コマンド
- ローカルサーバーの例
mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root ./mlflow-artifacts --host 127.0.0.1 --port 5001 - リモートサーバーの例
mlflow server --backend-store-uri postgresql://user:password@postgres:5432/mlflowdb --default-artifact-root s3://bucket_name --host remote_host --no-serve-artifacts
- ローカルサーバーの例
- 動作確認
import mlflow mlflow.set_tracking_uri(uri="http://127.0.0.1:5001/") mlflow.log_param("test", "test") print("The set tracking uri is ", mlflow.get_tracking_uri())Tracking Serverのテスト - サーバー構成
- Storage
- DB
- Cloud
- Network
- REST
- RPC
- Storage
- コマンド
- ビルトインのFlavor
- Python関数
- Spark MLlib
- Scikit-learn
- PyTorch
- TensorFlow
- OpenAI
- HuggingFace
- LangChain
- 1つのエクスペリメントに複数ランを1回のスクリプト実行で追加することも可能
- ハイパーパラメータ探索
- インクリメンタル学習
- モデルのチェックポインティング
- 特徴量エンジニアリング
- 交差検証
- モデルの保存方法
- save_model():MLflowトラッキングサーバーに限らず、任意のディレクトリにモデルを保存
- log_model():MLflowトラッキングサーバー内で指定したartifactsパス内にモデルを保存
- モデルのロード方法
- load_model():ローカルディレクトリ、アーティファクトパスの両方に対応
- モデルのバージョン、権限、リネージ、タグなどの管理も可能
- mlflowのシステムタグ一覧
mlflowのシステムタグ一覧
- mlflowのシステムタグ一覧
- モデルをバッチ処理でデプロイする利点は、保存された大量のデータを効率的に処理でき、並列処理によりパフォーマンス向上する点
- パイプラインデプロイメントの困難な部分は、ストリーミングデータ処理の複雑さ
- パイプラインデプロイメントで重要なのは、頑健なエラーハンドリング
- パイプラインデプロイメントの目的は、バッチ及びストリーミングデータ処理用DLTパイプラインの整備
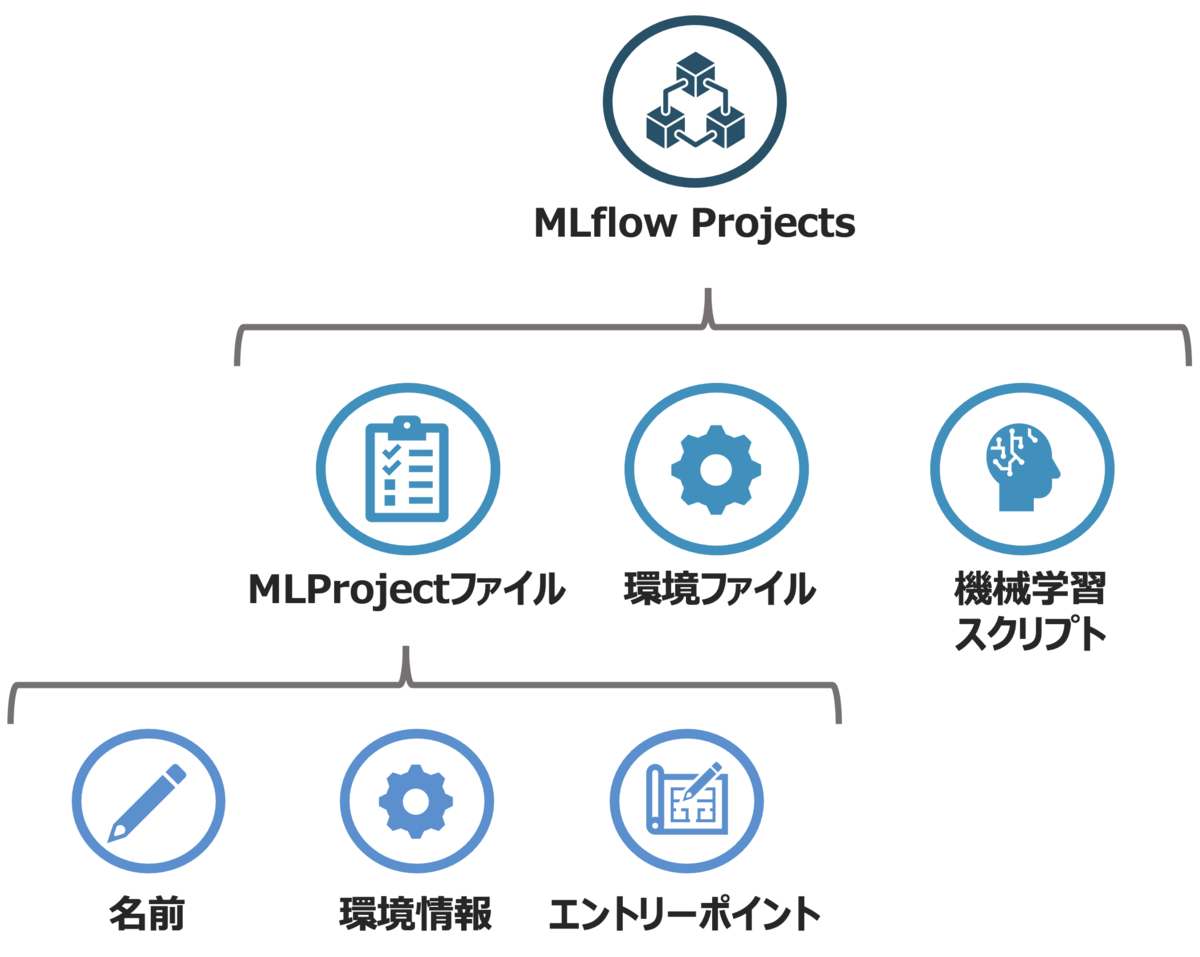
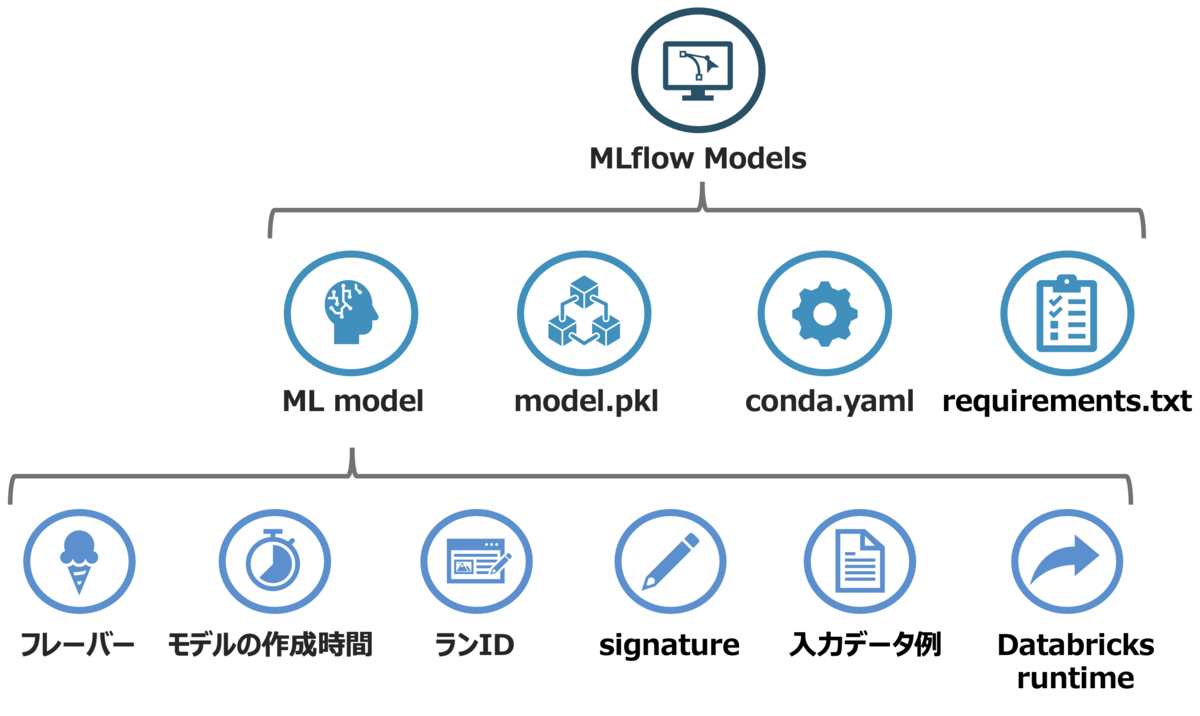
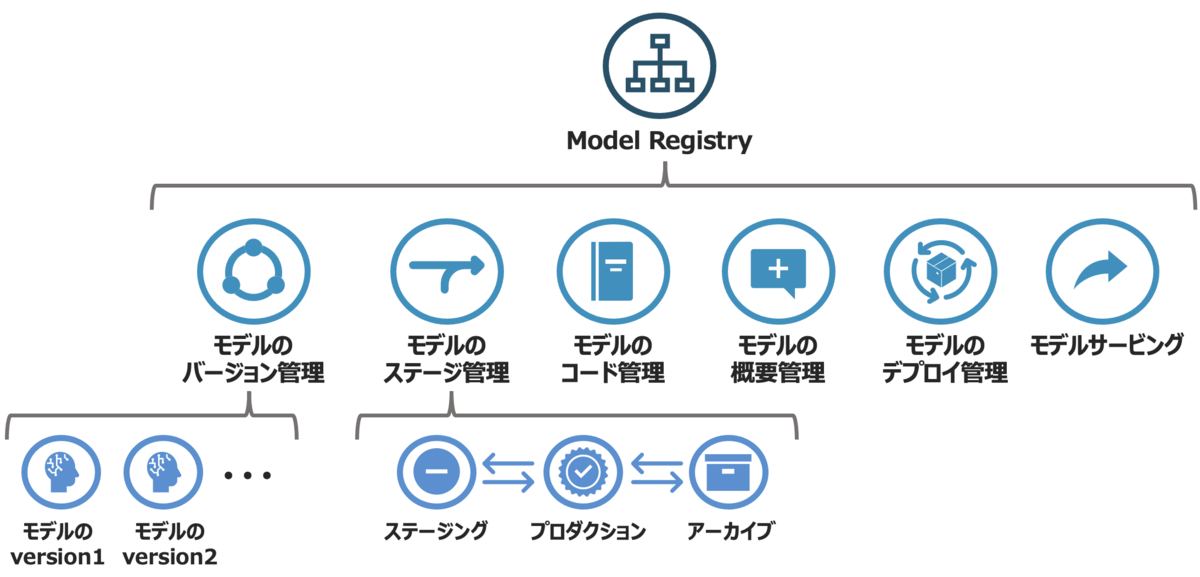

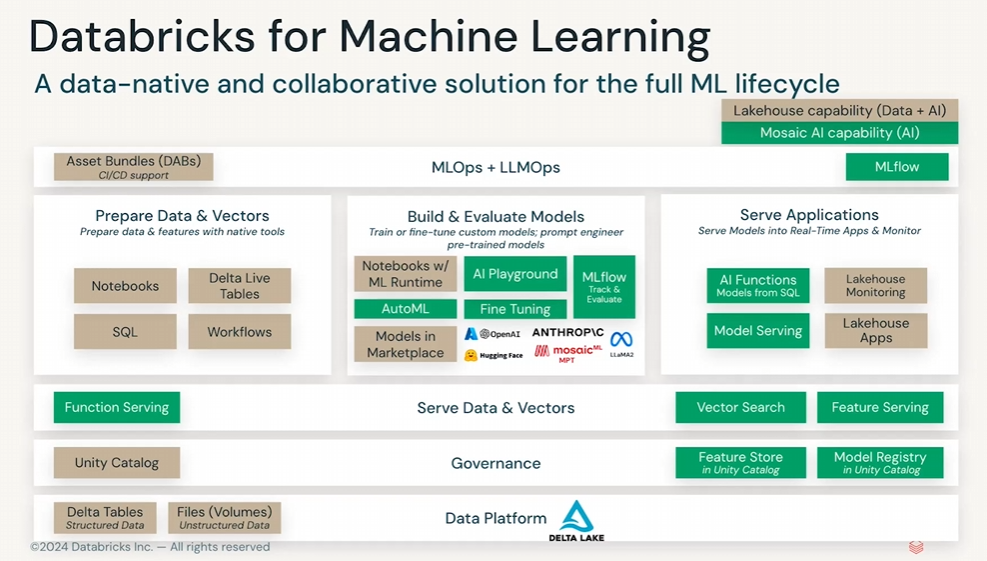
Databricks Model Serving
- 可用性、低レイテンシ、スケーラブルなモデルのサービング
- 自動特徴量参照、監視、統一ガバナンスにより自動デプロイメント
- サービング可能なモデル
- カスタムモデル:MLflow経由でいかなるモデルもREST APIとしてデプロイ可能
- 基盤モデル:Databricksが提供するクイックスタート可能なモデル
- 外部モデル:外部のAPIに対して、MLflowをゲートウェイとして活用することで、ガバナンス機能を提供
- エンドポイントの作成と管理は、REST API、Python SDK、Go SDKで可能
DatabricksにおけるDataOps
- 取り込みとデータ処理:Autoloader, Apache Spark
- 変更の取り込みと履歴管理:Delta Table
- データ加工パイプラインの管理:Delta Live Table
- データのセキュリティとガバナンス:Unity Catalog
- EDAとダッシュボード:Databricks SQL, Databricks Notebooks, Dashboards
- データパイプラインのスケジューリングと自動化:Databricks Workflows
- 特徴量の管理:Databricks Feature Store
- データ監視:Lakehouse Monitoring
Databricks Workflows Jobの概要
- Jobとして実行可能なモジュールの例
- Databricks Notebooks
- DLTパイプライン
- Python
- SQL
- dbt
- JAR
- Spark Submit
- フローの制御方法
- Sequential(逐次)
- Parallel(並列)
- Conditional(条件)
- Modular(タスクとしてモジュール化)
- トリガーの種類
- マニュアル
- Cron
- API
- File到着
- Delta Tableの更新
- ストリーミング
DatabricksにおけるModel Ops
- モデルライフサイクルの管理:Unity Catalogに保存されるモデル
- デプロイの追跡:MLflow Model Tracking
- モデルの監視:Lakehouse Monitoring
DatabricksにおけるDevOps
- データとモデルの管理:Unity Catalog
- RESTエンドポイントの提供:Mosaic AI Model Serving
- ワークロードの自動化:Databricks Workflows
- 推論環境の整備:Databricks Asset Bundles, Terraform, Databricks SDK, Databricks CLI
- CI/CD:Databricks Asset Bundles
- 監視:Lakehouse Monitoring
Databricks Asset Bundlesの運用手順
databricks bundle initでテンプレートを作成- 全てのコードを
srcフォルダに格納 databricks.ymlに環境やリソースに関する構成を記述databricks bundle deploy -e "dev"でバンドルをデプロイdatabricks bundle run pipeline -refresh-all -e "dev"でパイプラインを実行
各環境の役割
- Development:実験的にモデルを開発する環境
- Staging:開発したモデルをテストする環境
- Production:テストをパスしたモデルをデプロイする環境
環境の作成方法
- 直接分離
- 環境ごとにワークスペースを分離
- 1つのワークスペース内は単純化
- 複数プロジェクトでも利用可能
- 間接分離
- 1つのワークスペースの中に、Development/Staging/Productionが共存
- 1つのワークスペース内が複雑化
- プロジェクトごとにワークスペースを作成する必要がある
モデルの登録とデプロイ
- 登録
- Stageは以下の4段階
- None(特になし)
- Staging(テスト中)
- Production(本番運用中)
- Archived(お蔵入り)
- NoneとArchivedのモデルは、レジストリから削除可能
- StagingとProductionのモデルは、StageをNoneもしくはArchivedに変更すれば、レジストリから削除可能
- Stageは以下の4段階
- デプロイ方法
- コードデプロイ(推奨)
- モデルデプロイ
DatabricksにおけるMLOps
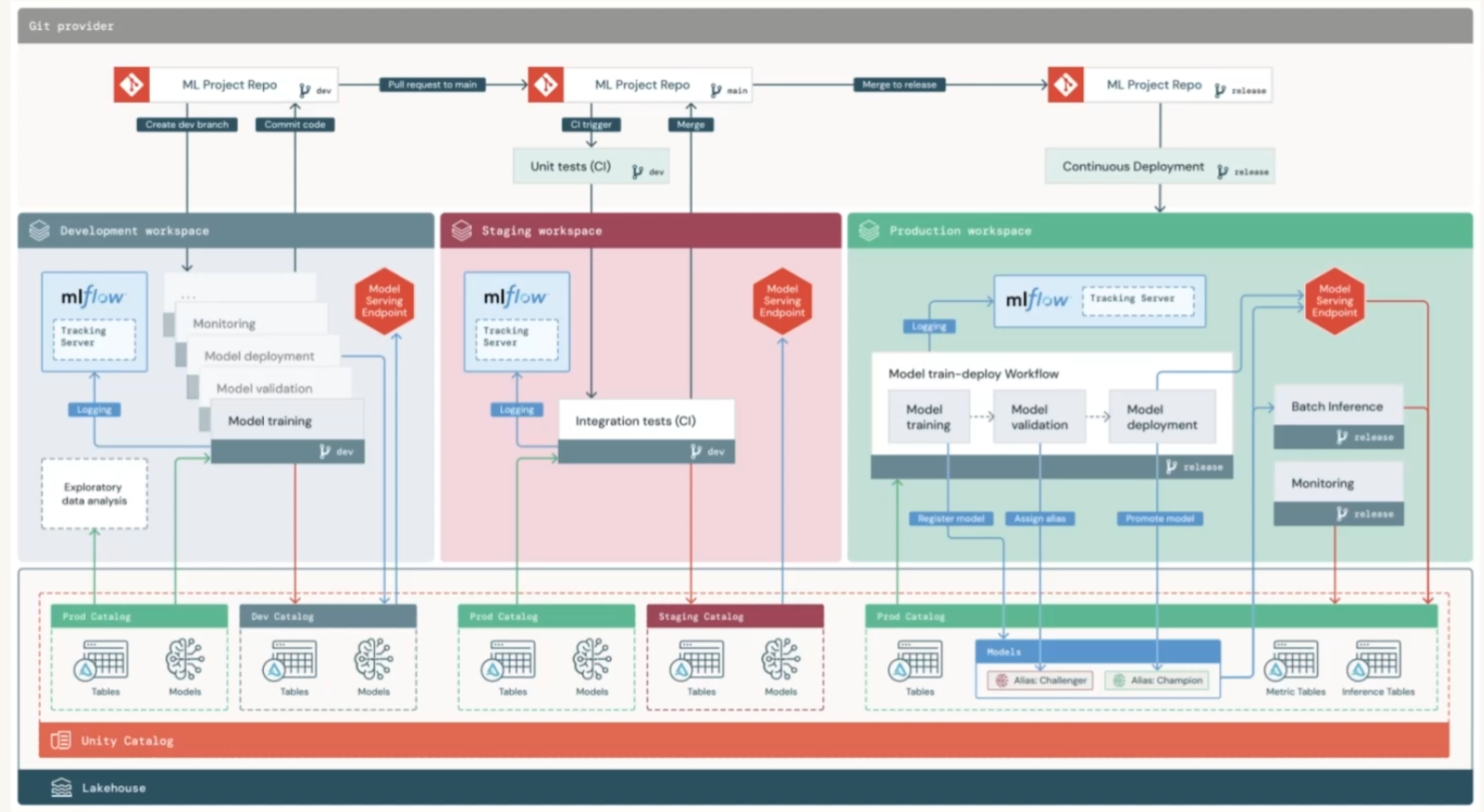
ドリフトの種類と対策
- Feature Drift(特徴量ドリフト)
- 概要
- モデルの入力データ(特徴量)の分布が、モデルの学習時の分布と異なる状態
- 例えば、購入履歴やユーザー行動パターンが季節やトレンドの変化で異なる場合
- 対策
- モニタリング: 特徴量ごとの分布を定期的にモニタリング
- データ生成過程の調査: データの変動原因を確認
- モデル再学習: データが変化した場合、新しいデータでモデルを再学習
- ロバスト性: データの変動を考慮したロバストなモデル設計
- 概要
- Label Drift(ラベルドリフト)
- 概要
- ターゲット変数(ラベル)の分布が時間とともに変化すること
- 例えば、ある時期における顧客の「購入確率」が、過去の時期と異なる場合
- 対策
- モニタリング: ラベルの分布や割合を定期的に確認
- サンプリング調整: 新しいラベル分布を考慮し、トレーニングデータのサンプリングを調整
- モデル再学習: 現在のラベル分布を反映したデータセットでモデルを再学習
- 概要
- Prediction Drift(予測ドリフト)
- 概要
- モデルが生成する予測値の分布が、期待される分布から逸脱する状態
- 例えば、モデルが突然すべての予測を「クラスA」とするような偏りが発生する場合
- 対策
- 予測モニタリング: 予測分布を継続的にモニタリング
- スライディングウィンドウ評価: モデルのパフォーマンスを時間軸に沿って評価
- オンライン学習: 新しいデータをモデルに取り込む仕組みを導入
- 概要
- Concept Drift(概念ドリフト)
- 概要
- 入力データとターゲットラベルの関係が時間とともに変化すること
- 例えば、ある特徴量が購入確率に強く関与していたのに、後には無関係になる場合
- 対策
- 特徴量エンジニアリング: 入出力間の関係をうまく表現できる説明変数の検討
- ドリフト検出: ウォッチドッグシステムを構築し、関係性の変化を検出
- アンサンブル学習: 複数のモデルを活用し、変化に強い予測を行う
- オンライン学習: モデルを新しいデータに合わせて継続的に更新
- フィードバックループ: ユーザーの行動や新しいデータを取り入れる仕組みを構築
- 概要
MLOpsで監視すべきメトリクス
ソフトウェア
- メモリ
- CPU/GPU使用率
- レイテンシ
- スループット
- サーバ負荷
入力データ
- 各列の統計量
- 最小
- 最大
- 平均
- 中央
- 分散
- 最頻
- ユニーク
- 欠損行の数
- 分布
- コルモゴロフ–スミルノフ (KS) 検定
- 概要
- 2つの分布が同じかどうかを評価する非パラメトリック検定
- サンプルの累積分布関数の最大差を利用
- 特徴
- KS統計量(累積密度関数の差の最大値)が大きいほど、2つの分布の類似度が小さい
- サンプルサイズに敏感で、大きなサンプルではわずかな分布の差でもP値が低下しやすい
- 分布の形状全体を比較するため、位置やスケールの変化を捉えられる
- 概要
- マン=ホイットニーのU検定
- 概要
- 対応のない2群の差を検出するための非パラメトリック検定
- 順序データでも使用可能
- 特徴
- サンプルサイズが小さい場合にも有効
- 分布全体の形状の違いには敏感ではない
- 概要
- ウィルコクソン検定
- 概要
- 対応のある2群の差を評価する非パラメトリック検定
- 特徴
- 対応のあるデータセットに適用可能
- 偏りの少ないサンプルを前提とする
- 概要
- ルビーン検定
- 概要
- 2つの分布の等分散性を検定するための統計手法
- 特徴
- 分散の違いに特化した検定
- 概要
- Wasserstein距離
- 概要
- 分布間の距離を評価する手法
- 分布を一致させるための「コスト」を計算
- 特徴
- 連続分布の形状の差異を定量的に評価可能
- サンプルサイズに依存しにくい
- 概要
- Kullback-Leibler (KL) Divergence
- 概要
- 一方の分布が他方の分布とどれだけ異なるかを測る非対称な指標
- 特徴
- 情報損失を評価するのに適している
- 外れ値に対して頑健
- 非対称性があり、対称的な測定をするには工夫が必要
- 概要
- Jensen–Shannon (JS) Divergence
- 概要
- KL Divergenceの対称版
- 2つの分布間の「平均的な差」を測定
- 特徴
- JS距離が小さいほど、分布の類似度が高い
- KSテストと異なりP値が算出されないため、自分で閾値を設定する必要がある
- サンプルサイズが増加しても変化が少なく、KS検定よりもロバスト
- 概要
- Population Stability Index (PSI)
- 概要
- 2つの分布(通常は実績値と期待値)の安定性を評価するための指標
- 特徴
- 信用リスクモデルやマーケティング分野でよく使われる
- しきい値に基づいて安定性を評価
- 概要
- カイ二乗適合度検定(One-way Chi-squared Test)
- 概要
- カテゴリデータの分布が期待値と一致するかを評価
- 特徴
- サンプルサイズが大きいほど結果が信頼できる
- 分布の形状の違いに対してやや鈍感
- 概要
- カイ二乗独立性検定(Chi-squared Contingency Test)
- 概要
- 2つのカテゴリ変数(クロス集計表の行と列)が独立であるかどうかを検定
- 特徴
- データが2次元のクロス表(分割表)に分類されている場合に使用
- 概要
- フィッシャーの正確確率検定
- 概要
- 小さいサンプルサイズでカテゴリデータの分布の一致を評価する検定
- 特徴
- サンプルサイズが小さい場合に適切
- 分布の偏りを精確に評価可能
- 概要
- ボンフェローニの補正
- 概要
- 多重検定を行う際に有意水準を補正する手法
- 各検定の有意水準を、全体の有意水準を検定回数で割った値に調整
- 特徴
- familywise error rateを制御するためにシンプルで広く利用される
- 保守的な手法であり、特に検定回数が多い場合に有意な結果を得にくくなる
- 概要
- コルモゴロフ–スミルノフ (KS) 検定
出力データ
- 予測値の統計量
- KPIなどのビジネス指標
モデルのリリース戦略
- Shadow
- モデルのデプロイは行っているものの、意思決定の参考には使用しない
- Rolling
- モデルのデプロイを1つのノードから開始し、逐次結果を確認してOKであれば、デプロイ対象のノード数を増やしていき、最終的にすべてのノードにモデルをデプロイ
- Blue-Green
- 2つのVerでデプロイするモデルをそれぞれ使い分け、環境を切り離してデプロイ
- Canary
- 1つの環境に2つの異なるVerのモデルをデプロイし、一部のユーザにのみ新しいバージョン、残りのユーザはこれまでのバージョンのモデルで対応
- A/B Testing
- Verの異なる複数のモデルが1つの環境に共存し、各モデルの評価と比較を実施
A/Bテストの評価指標
- 不正検知/解約予測:RP-AUC、ROC-AUC、f1
- 需要予測:AIC、BIC、RMSE、MAE
- 感情分析:BLEURT、BERTSCORE
実装
基本的な処理
- データフレームの統計値の確認
df.summary() - データスキーマの変換
df.withColumn("{col_name}", col("{col_name}").cast(StringType())) - フィルタリング
df.filter(col("{col_name}")>100) - 列に対する条件処理
df.withColumn("{col_name}", when(col("{col_name}")==1, True).otherwise(False)) - 欠損値の補完
bool_cols = [c.name for c in df.schema.fields if (c.dataType==BooleanType())] df_imputed = df.na.fill(value=False, subset=bool_cols)
機械学習関連の処理
- カテゴリ列のエンコーディング
from pyspark.sql import SparkSession from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType # Sparkセッションの作成 spark = SparkSession.builder \ .appName("FeatureEngineeringExample") \ .getOrCreate() # サンプルデータの作成 data = [ ("Tokyo", "IT", 35, 5000), ("Osaka", "Sales", 42, 6000), ("Nagoya", "HR", 28, 4500), ("Fukuoka", "IT", 31, 5500), ("Sapporo", "Sales", 39, 5800) ] # スキーマの定義 schema = StructType([ StructField("city", StringType(), True), StructField("department", StringType(), True), StructField("age", IntegerType(), True), StructField("salary", IntegerType(), True) ]) # DataFrameの作成 df = spark.createDataFrame(data, schema) # カテゴリカル変数のインデックス化 city_indexer = StringIndexer(inputCol="city", outputCol="city_index") dept_indexer = StringIndexer(inputCol="department", outputCol="dept_index") # インデックス化の実行 indexed_df = city_indexer.fit(df).transform(df) indexed_df = dept_indexer.fit(indexed_df).transform(indexed_df) # One-Hot Encoding city_encoder = OneHotEncoder(inputCols=["city_index"], outputCols=["city_ohe"]) dept_encoder = OneHotEncoder(inputCols=["dept_index"], outputCols=["dept_ohe"]) # エンコーディングの実行 encoded_df = city_encoder.fit(indexed_df).transform(indexed_df) encoded_df = dept_encoder.fit(encoded_df).transform(encoded_df) # ベクトルアセンブラを使用して特徴量を結合 assembler = VectorAssembler( inputCols=["city_ohe", "dept_ohe", "age", "salary"], outputCol="features" ) # 最終的な特徴量ベクトルの作成 final_df = assembler.transform(encoded_df) - 連続値をカテゴリに変換
from pyspark.sql import SparkSession from pyspark.ml.feature import Bucketizer # SparkSessionの作成 spark = SparkSession.builder.appName("BucketizerExample").getOrCreate() # サンプルデータフレームの作成 data = [ (0.5, ), # 0.5年 (1.5, ), # 1.5年 (3.0, ), # 3.0年 (4.5, ) # 4.5年 ] columns = ["duration_years"] df = spark.createDataFrame(data, columns) # Bucketizerの設定 splits = [float('-inf'), 1.0, 3.0, float('inf')] # 1年未満, 1~3年, 3年以上 bucketizer = Bucketizer( splits=splits, inputCol="duration_years", outputCol="category" ) # データの変換 bucketed_df = bucketizer.transform(df) # カテゴリのラベル付け(オプションで使える) category_labels = ["<1 year", "1-3 years", ">3 years"] bucketed_df = bucketed_df.withColumn( "category_label", bucketed_df["category"].cast("int") ).replace( {i: label for i, label in enumerate(category_labels)}, subset=["category_label"] ) # 結果を表示 bucketed_df.show() - スケーリング
- StandardScaler
- 平均と分散を用いてスケーリング
- 外れ値に敏感
- RobustScaler
- 中央値と四分位範囲を用いてスケーリング
- 外れ値に頑健
- データの分布が非正規分布の場合にも有効
from pyspark.ml.feature import StandardScaler, RobustScaler from pyspark.ml.linalg import Vectors data = [(Vectors.dense([10.0, 200.0, 3000.0]),), (Vectors.dense([20.0, 300.0, 4000.0]),)] df = spark.createDataFrame(data, ["features"]) # StandardScaler ss = StandardScaler(inputCol="features", outputCol="scaled_features", withMean=True, withStd=True) model_ss = ss.fit(df) df_ss = model_ss.transform(df) df_ss.show() # RobustScaler rs = RobustScaler(inputCol="features", outputCol="scaled_features", withCentering=True, withScaling=True) model_rs = rs.fit(df) df_rs = model_rs.transform(df) df_rs.show() - StandardScaler
- 欠損値の補完
from pyspark.sql import SparkSession from pyspark.ml.feature import Imputer spark = SparkSession.builder.appName("ImputerExample").getOrCreate() data = [(1.0, 2.0), (2.0, None), (None, 3.0), (4.0, 5.0)] columns = ["feature1", "feature2"] df = spark.createDataFrame(data, columns) imputer = Imputer(inputCols=["feature1", "feature2"], outputCols=["feature1_imputed", "feature2_imputed"], strategy="mean").setMissingValue(-1) # -1を欠損値として扱う model = imputer.fit(df) imputed_df = model.transform(df) imputed_df.show()
FeatureStoreの使い方
- テーブルの作成
- テーブルを登録する際は、目的変数(Target)を登録しないように注意
from databricks.feature_engineering import FeatureEngineeringClient fe = FeatureEngineeringClient() fe.create_table( name="{table_name}", primary_keys=["user_id"], df = df_feature, # df の指定はなくても良い description="User features", tags={"format": "delta"} ) - テーブルの読み込み
# 特定の特徴量テーブルのメタデータを取得 ft_meta = fe.get_table("{table_name}") ft_df = fe.read_table( name="{table_name}", as_of_delta_timestamp = timestamp_v2 ) - 特徴量の追加
# DataFrameから追加 fe.write_table{ name="{table_name}" df = df.select("{primary_key}", "{add_column}"), mode = "merge" # overwrite か merge を選択 } # Featureオブジェクトから追加 fe.add_features( table_name="{table_name}", features=[ Feature(name="is_active", dtype="boolean"), ] )
MLflowの使い方
- データの読み込み
import mlflow df = mlflow.data.load_delta( table_name = "{catalog_name}.{schema_name}.{table_name}", name = "{table_name}" ) - 実験管理
import mlflow params = { "max_depth": max_depth } tags = { "release.version": "1.0" } # mlflowの出力の保存先を指定(デフォルトはカレントディレクトリの mlruns フォルダ) mlflow.set_tracking_uri(uri="") print("The set tracking uri is ", mlflow.get_tracking_uri()) # エクスペリメントの作成 exp = mlflow.set_experiment(experiment_name="experment_1") # ランの実行 # 既存エクスペリメントに新規ランを追加する場合 with mlflow.start_run(experiment_id=exp.experiment_id, run_name="{run_name}") as run: # 既存ランに対して追加修正する場合 # with mlflow.start_run(run_id="{run_id}") as run: run_id = run.info["run_id"] mlflow.log_input(df, context="source") mlflow.log_params(param_dict) mlflow.set_tags(tags) artifacts_uri = mlflow.get_artifact_uri() print("The artifact path is", artifacts_uri) from mlflow.client import MLflowClient client = MLflowClient() fig=plt.figure() client.log_figure(run_id, figure=fig, artifact_file="plot.png") client.log_artifact(df) # ファイルを保存するときは log_artifact client.log_artifacts({folder}) # ファイルを複数保存するときは、複数のファイルを1つのフォルダにまとめて log_artifacts を使用 - Run情報の取得
from mlflow.client import MLflowClient client = MLflowClient() client.list_run_infos({experiment_id}) - Auto-logging
- mlflow.autolog(), mlflow.{flavor}.autolog() は fit や train の前で宣言する
- mlflow.{flavor}.autolog() は {flavor}ごとに引数が異なる
# evaluation function def eval_metrics(actual, pred): rmse = np.sqrt(mean_squared_error(actual, pred)) mae = mean_absolute_error(actual, pred) r2 = r2_score(actual, pred) return rmse, mae, r2 # Read the wine-quality csv file from the URL data = pd.read_csv("red-wine-quality.csv") #os.mkdir("data/") data.to_csv("data/red-wine-quality.csv", index=False) # Split the data into training and test sets. (0.75, 0.25) split. train, test = train_test_split(data) train.to_csv("data/train.csv") test.to_csv("data/test.csv") # The predicted column is "quality" which is a scalar from [3, 9] train_x = train.drop(["quality"], axis=1) test_x = test.drop(["quality"], axis=1) train_y = train[["quality"]] test_y = test[["quality"]] alpha = args.alpha l1_ratio = args.l1_ratio mlflow.set_tracking_uri(uri="") print("The set tracking uri is ", mlflow.get_tracking_uri()) exp = mlflow.set_experiment(experiment_name="experiment_autolog") #get_exp = mlflow.get_experiment(exp_id) mlflow.start_run() tags = { "engineering": "ML platform", "release.candidate":"RC1", "release.version": "2.0" } mlflow.set_tags(tags) mlflow.autolog( log_input_examples=True ) lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42) lr.fit(train_x, train_y) predicted_qualities = lr.predict(test_x) (rmse, mae, r2) = eval_metrics(test_y, predicted_qualities) mlflow.log_artifact("red-wine-quality.csv") artifacts_uri=mlflow.get_artifact_uri() print("The artifact path is",artifacts_uri ) mlflow.end_run() run = mlflow.last_active_run() print("Active run id is {}".format(run.info.run_id)) print("Active run name is {}".format(run.info.run_name)) - ハイパーパラメータ最適化
- 各ハイパーパラメータセットの結果を1つのランとして記録し、mlflow.start_run(nested=True) を使用してクロスバリデーションの各分割スコアをロギング
import mlflow import mlflow.sklearn from hyperopt import fmin, tpe, hp, Trials, STATUS_OK from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score from sklearn.metrics import accuracy_score import numpy as np # データセットのロード data = load_iris() X, y = data.data, data.target # ハイパーパラメータ空間の定義 space = { "n_estimators": hp.choice("n_estimators", range(10, 201, 10)), "max_depth": hp.choice("max_depth", range(1, 21)), "min_samples_split": hp.uniform("min_samples_split", 0.1, 1.0) } # 評価関数の定義 def objective(params): """ 目的関数: Hyperoptが最小化する目標。 """ with mlflow.start_run(nested=True): mlflow.log_params(params) # モデルの初期化 model = RandomForestClassifier( n_estimators=params["n_estimators"], max_depth=params["max_depth"], min_samples_split=params["min_samples_split"] ) # クロスバリデーション cv_scores = cross_val_score(model, X, y, cv=5, scoring="accuracy") mean_score = np.mean(cv_scores) mlflow.log_metric("mean_cv_accuracy", mean_score) # 各スプリットのスコアをログ for i, score in enumerate(cv_scores): mlflow.log_metric(f"cv_split_{i+1}_accuracy", score) # 目的関数の出力 return {"loss": -mean_score, "status": STATUS_OK} # ハイパーパラメータ探索 with mlflow.start_run(run_name="Hyperopt_CV_Experiment"): trials = Trials() best_params = fmin( fn=objective, space=space, algo=tpe.suggest, max_evals=50, trials=trials ) mlflow.log_params(best_params) print(f"Best Parameters: {best_params}") - 最も精度の高い結果の取得
# mlflow APIを用いた実装 from mlflow.entities import ViewType hpo_runs_fd = mlflow.search_runs( experiment_ids = [run.info.run_id] filter_string = "{filter_condition}", order_by = ["metrics.cv_f1 DESC"] ) # PySpark APIを用いた実装 import pyspark.sql.functions import col runs_df = spark.read.format("mlflow-experiment").load(run.info.run_id) hpo_runs_df = runs_df.where("{filter_condition}").withColumn("cv_f1"), col("metrics").getItem("cv_f1").orderBy(col("cv_f1.desc()")) - モデルをトレーニングし、特徴量テーブルを使用してバッチ推論
import mlflow from sklearn import linear_model feature_lookups = [ FeatureLookup( table_name='ml.recommender_system.customer_features', feature_names=['total_purchases_30d'], lookup_key='customer_id', ), FeatureLookup( table_name='ml.recommender_system.product_features', feature_names=['category'], lookup_key='product_id' ) ] fe = FeatureEngineeringClient() with mlflow.start_run(): # df has columns ['customer_id', 'product_id', 'rating'] training_set = fe.create_training_set( df=df, feature_lookups=feature_lookups, label='rating', exclude_columns=['customer_id', 'product_id'] ) # "training_df" columns ['total_purchases_30d', 'category', 'rating'] training_df = training_set.load_df().toPandas() X_train = training_df.drop(['rating'], axis=1) y_train = training_df.rating model = linear_model.LinearRegression().fit(X_train, y_train) fe.log_model( model=model, artifact_path="recommendation_model", flavor=mlflow.sklearn, training_set=training_set, registered_model_name="recommendation_model" ) # Batch推論(batch_dfの特徴量カラム+モデルの予測値のカラム) fe = FeatureEngineeringClient() predictions = fe.score_batch( model_uri=model_uri, df=batch_df ) - カスタムMLflowモデルの作成
import mlflow from mlflow.pyfunc import PythonModel class MyCustomModel(PythonModel): def __init__(self, model_path): self.model = load_model(model_path) def predict(self, context, model_input): # 予測処理 return self.model.predict(model_input) model = MyCustomModel({python_model}) with mlflow.start_run() as run: run_id = run.info.run_id model.pyfunc.save_model(model, {model_name}) # runから選択する場合 model_path = f"run:/{run_id}/{model_name}" model = mlflow.pyfunc.load_model(model_path) # modelから選択する場合 model_version_path = f"models:/{model_name}/{version}" model = mlflow.pyfunc.load_model(model_version_path)# 実装例 import warnings import argparse import logging import pandas as pd import numpy as np from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score from sklearn.model_selection import train_test_split from sklearn.linear_model import ElasticNet import mlflow import mlflow.sklearn from pathlib import Path import os from mlflow.models.signature import ModelSignature, infer_signature from mlflow.types.schema import Schema,ColSpec import sklearn import joblib import cloudpickle logging.basicConfig(level=logging.WARN) logger = logging.getLogger(__name__) # get arguments from command parser = argparse.ArgumentParser() parser.add_argument("--alpha", type=float, required=False, default=0.4) parser.add_argument("--l1_ratio", type=float, required=False, default=0.4) args = parser.parse_args() # evaluation function def eval_metrics(actual, pred): rmse = np.sqrt(mean_squared_error(actual, pred)) mae = mean_absolute_error(actual, pred) r2 = r2_score(actual, pred) return rmse, mae, r2 if __name__ == "__main__": warnings.filterwarnings("ignore") np.random.seed(40) # Read the wine-quality csv file from the URL data = pd.read_csv("red-wine-quality.csv") #os.mkdir("data/") data.to_csv("data/red-wine-quality.csv", index=False) # Split the data into training and test sets. (0.75, 0.25) split. train, test = train_test_split(data) data_dir = 'red-wine-data' if not os.path.exists(data_dir): os.makedirs(data_dir) data.to_csv(data_dir + '/data.csv') train.to_csv(data_dir + '/train.csv') test.to_csv(data_dir + '/test.csv') # The predicted column is "quality" which is a scalar from [3, 9] train_x = train.drop(["quality"], axis=1) test_x = test.drop(["quality"], axis=1) train_y = train[["quality"]] test_y = test[["quality"]] alpha = args.alpha l1_ratio = args.l1_ratio mlflow.set_tracking_uri(uri="") print("The set tracking uri is ", mlflow.get_tracking_uri()) exp = mlflow.set_experiment(experiment_name="experiment_custom_sklearn") #get_exp = mlflow.get_experiment(exp_id) print("Name: {}".format(exp.name)) print("Experiment_id: {}".format(exp.experiment_id)) print("Artifact Location: {}".format(exp.artifact_location)) print("Tags: {}".format(exp.tags)) print("Lifecycle_stage: {}".format(exp.lifecycle_stage)) print("Creation timestamp: {}".format(exp.creation_time)) mlflow.start_run() tags = { "engineering": "ML platform", "release.candidate":"RC1", "release.version": "2.0" } mlflow.set_tags(tags) mlflow.sklearn.autolog( log_input_examples=False, log_model_signatures=False, log_models=False ) lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42) lr.fit(train_x, train_y) predicted_qualities = lr.predict(test_x) (rmse, mae, r2) = eval_metrics(test_y, predicted_qualities) print("Elasticnet model (alpha={:f}, l1_ratio={:f}):".format(alpha, l1_ratio)) print(" RMSE: %s" % rmse) print(" MAE: %s" % mae) print(" R2: %s" % r2) mlflow.log_params({ "alpha": 0.4, "l1_ratio": 0.4 }) mlflow.log_metrics({ "rmse": rmse, "r2": r2, "mae": mae }) sklearn_model_path = "sklearn_model.pkl" joblib.dump(lr, sklearn_model_path) artifacts = { "sklearn_model" : sklearn_model_path, "data" : data_dir } class SklearnWrapper(mlflow.pyfunc.PythonModel): def load_context(self, context): self.sklearn_model = joblib.load(context.artifacts["sklearn_model"]) def predict(self, context, model_input): return self.sklearn_model.predict(model_input.values) # Create a Conda environment for the new MLflow Model that contains all necessary dependencies. conda_env = { "channels": ["defaults"], "dependencies": [ "python={}".format(3.10), "pip", { "pip": [ "mlflow=={}".format(mlflow.__version__), "scikit-learn=={}".format(sklearn.__version__), "cloudpickle=={}".format(cloudpickle.__version__), ], }, ], "name": "sklearn_env", } mlflow.pyfunc.log_model( artifact_path="sklear_mlflow_pyfunc", python_model=SklearnWrapper(), artifacts=artifacts, code_path=["main.py"], conda_env=conda_env ) artifacts_uri = mlflow.get_artifact_uri("sklear_mlflow_pyfunc") mlflow.evaluate( artifacts_uri, test, targets="quality", model_type="regressor", evaluators=["default"] ) run = mlflow.active_run() ld = mlflow.pyfunc.load_model(model_uri="runs:/{run.info.run_id}/sklear_mlflow_pyfunc") predicted_qualities=ld.predict(test_x) (rmse, mae, r2) = eval_metrics(test_y, predicted_qualities) print(" RMSE_test: %s" % rmse) print(" MAE_test: %s" % mae) print(" R2_test: %s" % r2) artifacts_uri=mlflow.get_artifact_uri() print("The artifact path is",artifacts_uri ) mlflow.end_run() run = mlflow.last_active_run() print("Active run id is {}".format(run.info.run_id)) print("Active run name is {}".format(run.info.run_name)) - モデルの登録
# 登録 model_path = f"runs:/{run_id}/{model_name}" register_name = {model_register_name} model_details = mlflow.register_model(model_uri=model_path, name=register_name) # 登録状況の確認 from mlflow.tracking.client import MLflowClient client = MLflowClient() model_version_details = client.get_model_version(name={model_name}, version=1) print(model_version_details.status) # モデルのロード model_path = f"models:/{register_name}" load_model = mlflow.pyfunc.load_model(model_uri=model_path) pred = load_model.predict(x_test) - モデルのステージ管理
from mlflow.tracking.client import MLflowClient client = MLflowClient() client.transition_model_version_stage( name = {model_name}, version = {model_version}, stage = "production" ) - モデルを使用した推論
import mlflow from pyspark.sql.functions import struct, col saved_model = f"runs:{run_id}/{model_name}" # Spark Dataframeに対する推論 model = mlflow.pyfunc.spark_udf(spark, model_uri=saved_model, result_type={data_type}) df.withColumn("predictions", model(struct(*map(col, df.columns)))) # Pandas Dataframeに対する推論 import pandas as pd model.predict(pd.DataFrame(data)) - FeatureStoreを活用したバッチ推論
from pyspark.sql.functions import monotonically_increasing_id from mlflow.models.signature import infer_signature import mlflow.sklearn # Initialize Feature Store client fe = FeatureStoreClient() # Load and prepare data input_csv_path = "airbnb-cleaned-mlflow.csv" # Replace with your dataset path df = (spark.read .csv(input_csv_path, header=True, inferSchema=True) .withColumn("index", monotonically_increasing_id())) # Split data into features and inference data features_df = df.drop("price") inference_df = df.select("index", "price") # Define feature table name feature_table_name = "your_schema_name.airbnb_features" # Replace with your schema and table name # Create feature table fe.create_table( name=feature_table_name, primary_keys=["index"], df=features_df, description="Airbnb feature table" ) # Define FeatureLookup feature_lookups = [FeatureLookup( table_name=feature_table_name, feature_names=None, # Include all features lookup_key="index" )] # Create training set training_set = fe.create_training_set( inference_df, feature_lookups, label="price", exclude_columns="index" ) # Log a model using the feature store suffix = "unique_suffix" # Replace with a unique identifier model_name = f"airbnb_model_{suffix}" # Assuming you have a trained RandomForest model from sklearn.ensemble import RandomForestRegressor rf_model = RandomForestRegressor() X, y = None, None # Replace with actual features and labels fe.log_model( model=rf_model, artifact_path="feature_store_model", flavor=mlflow.sklearn, training_set=training_set, registered_model_name=model_name, input_example=X[:5], # Replace with actual input examples signature=infer_signature(X, y) # Replace with actual input and output ) # Perform batch scoring batch_input_df = inference_df.drop("price") # Exclude true label with_predictions = fe.score_batch(f"models:/{model_name}/1", batch_input_df, result_type='double') # Display results display(with_predictions)
AutoML APIの使い方
- 一連の流れ
import mlflow import sklearn from sklearn.model_selection import train_test_split from databricks import automl # データの読み込み input_pdf = sklearn.datasets.fetch_california_housing(as_frame=True) display(input_pdf.frame) train_pdf, test_pdf = train_test_split(input_pdf.frame, test_size=0.01, random_state=42) # 学習 summary = automl.regress(train_pdf, target_col="MedHouseVal", timeout_minutes=10) model_uri = summary.best_trial.model_path # 予測 y_test = test_pdf["MedHouseVal"] X_test = test_pdf.drop("MedHouseVal", axis=1) model = mlflow.pyfunc.load_model(model_uri) predictions = model.predict(X_test) test_pdf["MedHouseVal_predicted"] = predictions display(test_pdf)